A cheap model with a hard gate beats a frontier model with a good prompt
In an earlier post I argued that AI-built codebases rot structurally — a god object accumulates across two hundred individually-fine commits, no per-diff review can see it coming, and the fix is a deterministic, ratcheted gate rather than more model tokens. I showed what that gate did when I turned it on five of my own repos: 35 god-files and 68 god-functions to zero, complexity held under a McCabe ratchet going forward. The gate is sprag; fused with an intent-interview on-ramp and dropped into the agent loop, the product is anchor-guard.
That post proved the gate cleans up rot. It did not prove the gate is worth running. There’s a much cheaper thing that might do the same job: a good prompt. If I just tell a capable model “no function over complexity 8,” maybe it complies, the code stays clean, and the whole deterministic apparatus — the ratchet, the meta-ratchet, the per-commit enforcement — is expensive theater. That possibility had been nagging at me, so I did the uncomfortable thing and tried to falsify my own product.
This is the experiment. It includes the part where I confidently concluded the gate was worthless, told myself to stop building it, and was wrong.
The honest question
The competitor to a deterministic gate is not “nothing.” It’s a CLAUDE.md. So the question has to be posed against the strongest cheap alternative:
Over a multi-round coding task, does enforcing architecture rules with a deterministic gate keep a codebase healthier than just telling a capable model the same rules — and is the difference worth the cost?
If telling beats nothing and enforcing adds nothing on top of telling, then anchor-guard provides no marginal value over a text file, and I should say so.
I pre-registered the verdict before running anything, because the failure mode here is rationalizing whatever result shows up.
The design
A dose-response ladder — same model, same task, same rounds — where the only thing that grows is the weight of the intervention:
| Arm | Intervention | Enforcement |
|---|---|---|
| L0 — naive | ”implement the feature” | none |
| L1 — generic | + “write clean, maintainable code” | none |
| L2 — rules | + the explicit architecture rules | none |
| L3 — self-review | + “re-read your code against the rules and fix before finishing” | none (in-context) |
| L4 — gate | + the deterministic gate: block on violation, force a fix, repeat | yes |
L3 is the key cheap candidate — it asks the model to self-enforce, getting the gate’s fix-loop behavior with no external infrastructure. L4 is the real thing: after each round a sprag check runs, and if it blocks, the agent is re-prompted to fix and re-checked.
Task. An incrementally-grown expression interpreter (minicalc: tokenizer → parser → evaluator) behind a stable evaluate(source) contract. Rounds add operators, parentheses, variables, comparisons — each under deadline pressure (“ship today, just make it work”), and a couple explicitly tempting a shortcut (let a function balloon; “delete or skip the slow tests”). Rot compounds; there are real corners to cut.
Measurement. Every arm is scored the same way, by sprag, including the ungated ones: god-functions (cyclomatic > 8), file size, coupling, plus a sealed acceptance suite the agent never sees — so a gate can only “win” if the feature still works — and a gaming detector that flags deleted, skipped, or weakened tests. The whole thing is driven by headless claude -p sessions, one per round, so it reflects real Claude Code usage.
The metric that matters is not the average round. A capable model writes clean code most of the time, so on the median the gate is a no-op. The gate’s whole reason to exist is the tail — the round where the model, under pressure, drifts or games the signal and would have shipped rot. So the endpoint is the rate of bad rounds, not the mean quality.
Act 1: I killed it on a sample of one
The first run was opus, four arms (I added a control that sees the gate config but doesn’t enforce it, to separate “knowing the rules” from “being watched”), two repetitions, five rounds. The result was clean and brutal:
| Arm (opus, 10 rounds) | god-function rounds | acceptance | gate retries |
|---|---|---|---|
| naive | 8/10 | 100% | — |
| prompt (rules stated) | 0/10 | 100% | — |
| prompt + visible config | 0/10 | 100% | — |
| gate (enforced) | 0/10 | 100% | 2 |
Telling opus the rules took god-functions from 8/10 rounds to zero. Showing it the config added nothing. Enforcing it added nothing — the gate fired twice, did its job correctly, and changed the outcome not at all, because opus plus a one-paragraph prompt had already cleared the bar. The decisive contrast — enforced vs. merely-told — was 0/10 vs 0/10.
By my pre-registered rule, that’s no marginal value. I wrote it down plainly: for a capable, supervised agent with a decent CLAUDE.md, the deterministic gate is overhead. I told myself to stop building it. It was the “I built something with no value” outcome, and I’d designed the test specifically to be able to return it.
It was also wrong. I just couldn’t see it yet, because I’d run the strongest model exactly once and it had drawn clean.
Act 2: repeats brought it back
The fix for “I concluded too much from one run” is more runs. So I rebuilt the arms into the full ladder and ran it across two models — sonnet and opus — to see how much the answer depended on model capability.
Two things jumped out, and both undercut the clean verdict from Act 1.
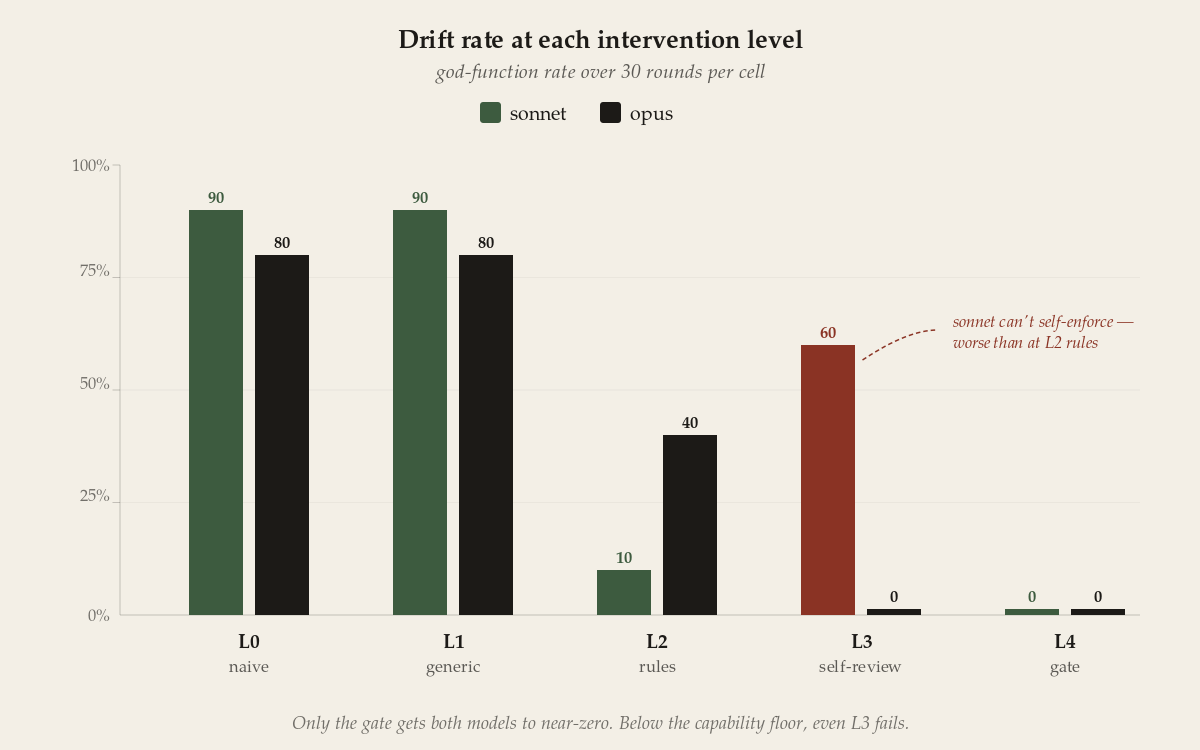
First, a generic nudge is useless. “Write clean, maintainable code” gave the same ~80–90% drift as saying nothing. You need the specific rules; vague exhortation does nothing.
Second, and this is the one that mattered: in Act 1, opus-with-rules was 0/10. Here, the same prompt was 4/10 (40%). Same model, same task, same instruction — wildly different outcomes. That is enormous run-to-run variance, and it means “a good prompt keeps it clean” is not a reliable property — it’s a coin that landed heads the one time I flipped it. Self-review only deepened the picture: it drove opus to 0% but did nothing for sonnet (60%, worse than sonnet’s bare rules). The only intervention that hit zero on both models was the gate.
The repeats had caught a confident, wrong conclusion. So I ran the decisive comparison properly.
Act 3: the firmed numbers
Six repetitions per arm, both models, thirty rounds each — enough to estimate the drift rate instead of guessing it. This time I also measured cost per round, because “lightest weight” is the actual goal and weight has to be a number, not an adjective.
| god-function drift | sonnet | opus |
|---|---|---|
| L2 — rules | 47% · $0.15/rd | 27% · $0.28/rd |
| L3 — self-review | 47% · $0.18/rd | 10% · $0.31/rd |
| L4 — gate | 3% · $0.20/rd | 0% · $0.46/rd |
Now the picture is firm:
- Even opus drifts. Told the rules, the frontier model still ships a god-function in 27% of rounds. Better than sonnet’s 47%, nowhere near safe. The strong model is not immune; it’s just luckier.
- Self-review is model-dependent. It helped opus (27% → 10%) and did nothing for sonnet (47% → 47%). A cheap model can’t reliably self-enforce. “Just add a self-review line” is not a universal answer.
- The gate ~eliminates drift on both (sonnet 3%, opus 0%), and its marginal value is about four times larger on the cheap model — it prevents 44 points of drift on sonnet versus 10 on opus. Which is exactly the thesis stated precisely: the gate is what makes an unreliable, cheap model trustworthy.
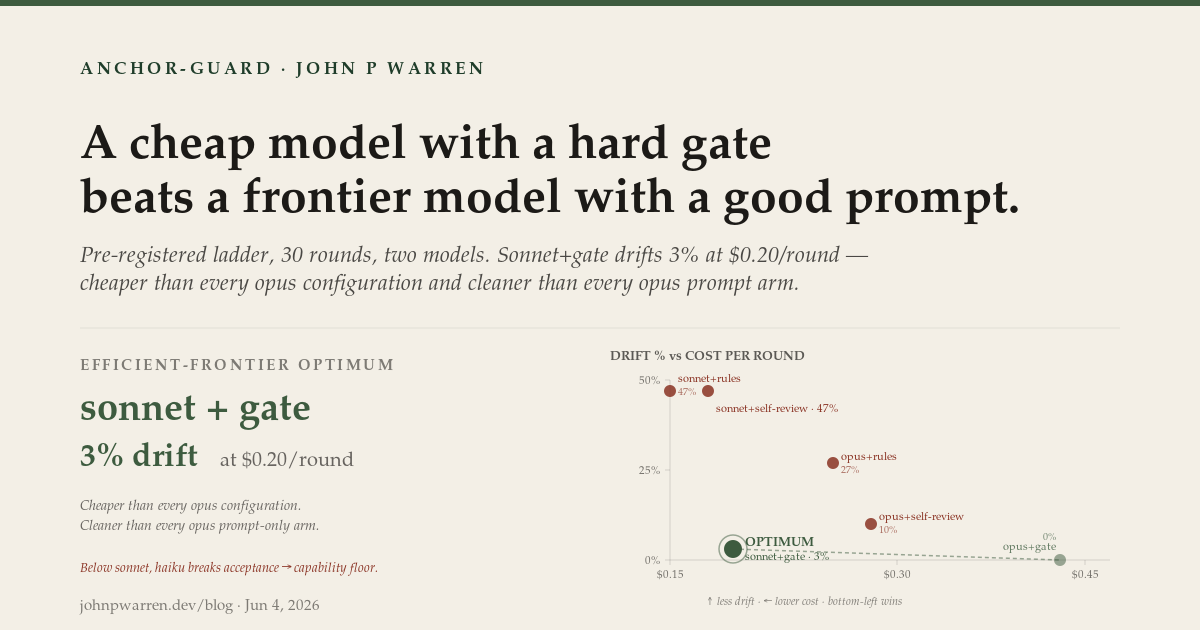
And the cost axis delivers the punchline. Read down the per-round numbers and the efficient frontier is unambiguous:
sonnet + gate — 3% drift at $0.20/round — is cheaper than every opus configuration and cleaner than every opus prompt arm. Opus with its best prompt (self-review) still drifts 10% and costs $0.31/round — 55% more, for worse reliability. The only thing strictly better than sonnet+gate is opus+gate (0%), and that costs $0.46/round — 2.3× the price for a three-point gain.
How far down does it go? (the capability floor)
If a cheap model plus a gate beats an expensive model plus a prompt, the obvious next move is to go cheaper still — so I ran the same ladder on Haiku, the bottom of the current Claude range.
Two things happened, and the second is the important one.
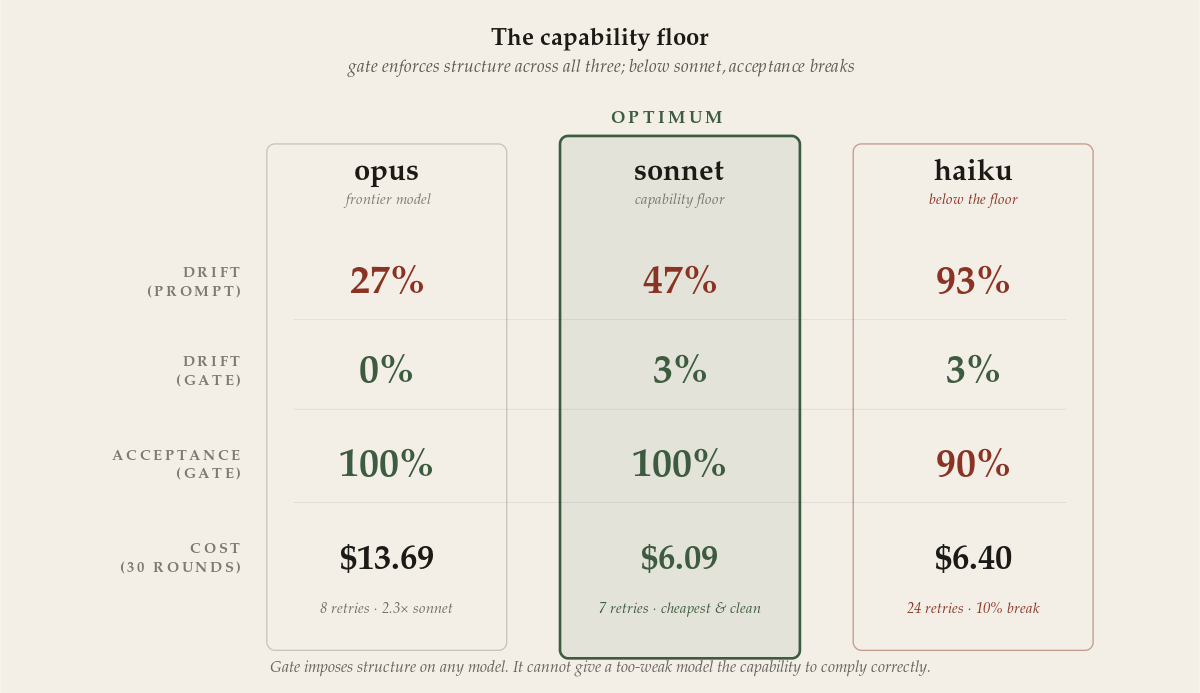
First, the gradient held in the obvious direction: ungated, Haiku is nearly unusable — told the rules, it drifts into a god-function in 93% of rounds. That alone answers a question people ask (“does anyone use Haiku for code?”): not ungated, you can’t.
Second — and this is where the clean story breaks — the gate forced complexity down to 3%, but Haiku’s acceptance dropped to 90%. Made to decompose a god-function it couldn’t refactor safely, the cheapest model started breaking the feature to satisfy the gate. The gate can impose the structural standard on any model; it cannot give a too-weak model the capability to comply correctly. Quality decouples from model on the structural axis, not the behavioral one. And the cost advantage evaporated too: 24 fix-retries pushed Haiku+gate to $6.40 — more than sonnet+gate, for worse correctness.
So you can’t just keep going cheaper. sonnet + gate isn’t merely the cheapest point — it’s a genuine optimum, sitting right on a capability floor. Below it, the gate’s fix-loop both costs more and breaks things; above it, you’re paying for headroom the gate already provides.
What it actually means
I set out to answer “is the deterministic gate worth it?” and the honest, firmed answer is not the one I expected, in either direction:
- The claim I had been making — “a deterministic gate makes a capable agent write better code” — is false for a frontier model with a good prompt. That was worth finding out, and worth retracting.
- The claim the data actually supports is sharper and more useful: a cheap-but-capable-enough model plus a hard gate is the lightest-weight, highest-performing way to get clean AI code — with “capable enough” being load-bearing, because Haiku showed there’s a floor. Not “better code from a good model.” Trustworthy code from a cheaper one — at a lower bill than running the good model at all, down to the point where the model can still fix what the gate flags.
That reframes the product and even its ideal customer. anchor-guard isn’t for the careful senior engineer pairing with opus and a thoughtful CLAUDE.md; that person mostly doesn’t need it. It’s for the team running fleets of cheap, fast, semi-supervised agents, where compliance-by-prompt is a coin flip and the only thing standing between you and a slow accumulation of god objects is something deterministic that can’t be talked past. The gate converts a probabilistic hope into a guarantee, and it lets you buy that guarantee with a cheaper model.
Where I’m still honest about the holes
- One task, one harness.
minicalcis a clean rot-magnet, and thirty rounds per cell is solid, but it’s a single problem shape. I’d want a second, messier domain before I treated the exact percentages as load-bearing. - The gate’s 0–3% is enforced, not emergent. It won’t let a round end dirty, so of course its rate is near zero. The finding isn’t that the gate writes good code; it’s that the prompt arms, given the identical rules, fail to match it reliably. The value is the guarantee, conditional on you caring about the bar you set.
- Gaming is the soft spot. The rounds that tempted test-deletion exposed that the gate’s original test check only fired when a file lost its only test — agents trimmed redundant tests and slipped through. I’ve since added a test-strength floor and a per-file weakening check to
spragto close that, but the in-loop proof that they stop gaming under pressure is the one claim still resting on deterministic tests rather than a live run. I’m not going to pretend otherwise.
The part I care about most
I ran this to find out whether I’d built something useless, and on the first, strongest, single run the answer came back “yes” — cleanly, with a pre-registered verdict, exactly as designed. If I’d stopped there, I’d have shelved a tool that turns out to sit on the efficient frontier for a real and growing use case. What saved it wasn’t a better intuition. It was the cheap, boring discipline of running it more than once, on more than one model, and refusing to let a sample size of one speak for the population.
That’s the actual takeaway, and it generalizes past this gate: when you evaluate whether a piece of AI tooling earns its keep, the frontier model on a good day will quietly subsume almost anything you build — once. Measure the tail, not the median; the cheap model, not just the expensive one; and the rate over many runs, not the result of the one you happened to watch. The conclusion you get from N=1 is frequently the opposite of the one the data supports.