Tessera: same engine, different scope, and what Anchor-from-round-1 looks like
The previous post in this series closed on a question: what changes when the operational scope is “100-10,000 GPU shards in a running cluster” rather than “one deploy decision”? This post is the answer.
Tessera is a sibling product to DeploySignal. It uses the same statistical engine — Families A/C/D/E, Ville-bounded e-processes, hierarchical baseline pooling — applied to a fundamentally different operational question. DeploySignal asks “should this canary deploy proceed?” once per deployment. Tessera asks “is this shard behaving normally?” continuously, for every shard in a running cluster, every tick.
The shift sounds small. It isn’t. Continuous observation across N shards introduces three problems that single-canary work doesn’t have: multiple testing (false positives compound across N concurrent verdicts), topology-aware grouping (a failure on three shards sharing a rack is a different signal than three uncorrelated shard failures), and known-disruption suppression (during a firmware push, statistical noise is expected, not a regression). Each gets a section below.
Tessera also has a different relationship to the methodology. DeploySignal was where Anchor emerged — the disciplines were distilled along the way, sometimes painfully. Tessera was built using Anchor from round 1, with about fifteen inherited disciplines plus the cross-project memorial. Seventy-eight rounds in, it’s the first project where I can compare “methodology applied from start” against “methodology distilled along the way.” The comparison is the second half of this post.
The operational shift
Tessera and DeploySignal share an engine. They don’t share an operational profile.
| DeploySignal | Tessera | |
|---|---|---|
| Scope | One canary deployment → one verdict | N shards of a running cluster → per-shard + cluster-wide observation |
| Stakeholder | Production SRE / deployment owner | Cluster oncall / AI infra operator |
| Output | Proceed / extend / rollback decision | Per-shard deviation attribution + fleet-event vs shard-fault distinction |
| Trigger | Each deployment | Continuous |
| Failure class | Canary-vs-stable statistical comparison | Per-shard SDC-class faults, topology-localized common-mode failures, event-conditional drift attribution |
The math substrate is identical: same betting e-processes, same Hotelling T² with Ledoit-Wolf shrinkage, same Mahalanobis novelty against weighted-conformal calibration. What changes is what the math is being asked to do.
In DeploySignal, the math compares one canary population to one stable baseline, produces one verdict, and stops. The α budget is allocated per family at compile time and spent across the canary window. The audit record is one verdict per deploy.
In Tessera, the math runs continuously per shard. For a 1,000-shard cluster, that’s a thousand concurrent verdict streams running at each tick. The α-budget question becomes: across all those streams, what’s the global false-positive rate, and what does an operator need to do to keep it bounded?
This is the multiple-testing problem, and it’s where continuous observation departs from single-canary semantics. Naive per-shard α-control at 1e-3 across 1,000 shards produces roughly one false positive per tick — useless. Tessera’s answer is e-BH FDR control, adapted for anytime-valid e-values rather than fixed-sample p-values. The other two problems — topology-aware grouping and known-disruption suppression — fall out of the per-shard architecture once the FDR problem is solved.
The technical core
Per-shard residuals
DeploySignal’s detector families are tuned for two-population comparison: canary vs. stable. Each signal is treated as a scalar (or vector) drawn from a distribution; the detector asks whether the canary draws are statistically distinguishable from the baseline draws.
Tessera’s residual semantics adapt the same detectors to per-shard observation. For each shard, the “baseline” isn’t another deployment — it’s a hierarchical pool combining (a) the shard’s own historical behavior, (b) the host the shard sits on, (c) the rack containing the host, and (d) the fleet at large. Pool weights resolve based on how much per-shard history is available and how strongly the host / rack / fleet layers concentrate.
Each tick produces a per-shard residual vector — observed signal minus pool prediction — and Families A/C/D/E run against those residuals exactly as they ran against canary signals in DeploySignal. Family A catches a shard drifting against its hierarchical baseline. Family C catches joint-distribution shifts in the residual vector. Family D catches periodic patterns appearing in residuals that should have been white-noise. Family E flags residual patterns that fall outside the fleet’s healthy calibration region.
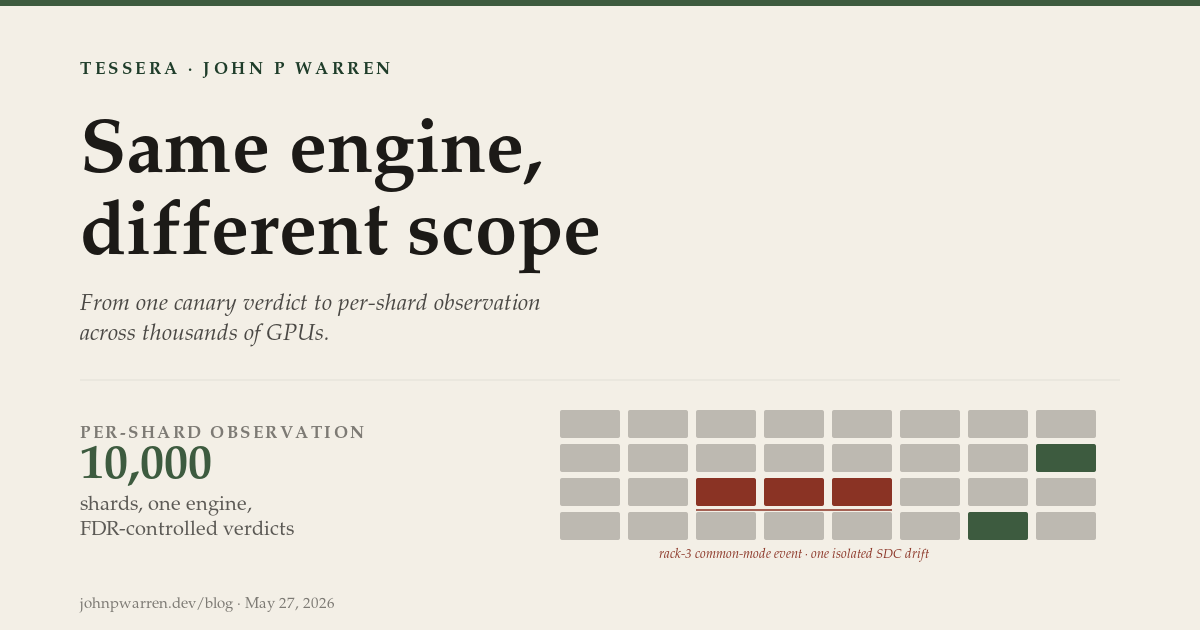
The architectural payoff: a shard with a silent SDC producing subtle correctness drift won’t fail any individual signal threshold, but its residual vector will look wrong against the hierarchical pool. The R72 saturation matrix measured this — at default settings, Tessera detects 18/20 sdc-drift trials with 100% attribution accuracy on the detected trials (correct shard identified).
e-BH FDR control
The multiple-testing problem is the central new statistical question. If N shards each run an α=1e-3 test at every tick, and shards behave independently under the null, the expected number of false positives per tick scales linearly: 1,000 shards × 1e-3 = 1 per tick. After thirty ticks, ~30 expected false positives — drowning whatever true signal exists.
Standard False Discovery Rate (FDR) control adjusts thresholds to keep the proportion of false positives among rejections bounded, not the total count. The classical Benjamini-Hochberg procedure does this for fixed-sample p-values. But Tessera’s detectors are anytime-valid e-processes; the wealth statistics are read continuously, not at a single stopping time. Applying BH to anytime-valid evidence would inflate FDR by an amount the standard analysis doesn’t bound.
The e-BH procedure (Wang & Ramdas, 2022, plus subsequent refinements) is the anytime-valid analogue. It controls FDR over the per-shard verdict surface at a target rate (Tessera defaults to 5%) while remaining valid at any stopping time the operator chooses. The trade is conservative: at equal nominal FDR, e-BH is slightly less powerful than fixed-sample BH would be. The trade is worth it because the alternative is silently invalid FDR claims.
Operationally: each tick, Tessera collects per-shard e-process values, runs e-BH at α_FDR=0.05, and rejects the subset that survives. The audit record carries per-shard verdict, per-shard e-value, the e-BH cutoff that tick, and the rejected set. R72 measured FDR control empirically across 20 parameter variations on the fdr-multiple-testing failure type: 20/20 detection rate with 100% attribution accuracy — the FDR guarantee held.
This is the load-bearing math claim of Tessera: continuous per-shard observation with formal FDR guarantees, not a heuristic “alert if N shards fire.”
Hierarchical e-value combination
Per-shard verdicts catch per-shard failures. They miss the case where a fleet event affects a topology-correlated subset — three shards on the same rack flapping together, an entire host degrading at once, a row of GPUs sharing a cooling zone showing correlated thermal drift. Per-shard FDR control might reject one of three correlated shards by chance and miss the structural signal.
Tessera’s hierarchical e-value combination runs in parallel with per-shard verdicts. At each tick, e-values from shards belonging to the same host, rack, or cooling zone are combined into a group-level e-value (by averaging — a valid combination for e-values under the union-of-nulls construction). Group-level e-values run their own e-BH FDR control at the host / rack / cooling-zone layer.
The result is a multi-layer verdict surface. A failure isolated to one shard produces a per-shard rejection. A failure correlated across three shards on the same rack produces a rack-level rejection at a per-shard severity that wouldn’t have crossed individual thresholds. The R72 matrix shows this directly: common-mode-rack scenarios detect at 20/20 in trials where per-shard alone would catch fewer.
The discipline is also what makes the freeze-hook (next section) tractable — operators get told “rack-7 is anomalous” rather than receiving sixteen per-shard alerts they need to manually correlate.
Topology-aware freeze-hook
Continuous statistical observation produces false positives during known disruptions. A rolling firmware push will produce correlated drift on every shard receiving the new firmware; that drift is expected, not a regression. Without suppression, the system would emit hundreds of confident-but-irrelevant alerts during routine operator activity.
Tessera’s freeze-hook consumes a FleetEvent stream — events that operators or the deploy pipeline emit when known disruptions are in progress. Each event carries a window (start time, expected duration), a topology scope (which shards or racks are affected), and an event kind (firmware push, rolling restart, scheduled maintenance). During an active event window for an affected shard, detection is suppressed; the audit record notes freeze_active: true with the event reference, but no verdict is emitted.
The event source matters. The bi-directional integration with DeploySignal provides one canonical event source — when DS emits a per-deploy verdict, Tessera’s DS event consumer ingests the deploy window and applies it as a freeze hook for affected shards. The contract at engine/ds-integration/ carries both directions: Tessera ships per-shard VerdictGroup observations to DS’s correlation layer, and DS ships deploy events to Tessera’s freeze-hook.
This is what makes the lifecycle composable rather than additive. DS knows about deploys; Tessera knows about cluster behavior; the two share state through structured contracts rather than guessing at each other’s data.
Vendor adapters
Per-shard observation needs to know what a shard is, which host it lives on, which rack the host occupies, and how the topology connects. Tessera ships six topology adapters: Slurm, Kubernetes, NVLink, AWS Neuron Trainium, AWS Neuron Inferentia (with Neuron Link topology), and Google TPU/ICI.
Each adapter normalizes its vendor-specific topology representation into a common TopologySnapshot interface. The adapter is the only vendor-aware code; once a snapshot is produced, the rest of Tessera operates on the same abstraction regardless of substrate.
A8 and A11 carve-outs are explicit: at v1, Tessera only consumes operator-controlled rental environments or synthetic fixtures derived from public Neuron SDK + JAX topology code + TPU v4/v5 papers. Real-cluster validation on rented hardware is a Phase 4 candidate (Path B selected at the SLICE 1/2 gate per OQ-P3-9). The honest version of the v1 claim: empirically grounded structurally, not on a running cluster.
The methodology applied from round 1
78 rounds, 440+ tests, what’s different
DeploySignal’s first twenty rounds produced multiple expensive failures of types I didn’t yet have explicit disciplines for. The Topic 52 phantom chain, the σ² compile-time underflow, the wrong-premise architect spec — each of those cost wall-clock days, and each produced a discipline I memorialized after the fact.
Tessera’s first twenty rounds had zero failures of those types.
Not because the work was easier — Tessera vendors a different operational scope onto the same engine, with new architectural surfaces (topology adapters, FDR control, hierarchical e-value combination), each with its own failure modes. But because the methodology was scaffolded from setup: Q-specs with explicit ## Existing architectural surface citation tables, cold-eye Reviewer audits on every emit, pre-route checklists with severity triage, memorial accretion live from round 1. The Anchor coordination/ directory mirrors DeploySignal’s structure. The role mapping was canonical from the first chat.
The cross-project memorial brought about fifteen inherited disciplines forward. Some applied directly (file-opened discipline, anti-self-confirming-test patterns); some applied with adjustment (the V/Q framework adapted from investigation-chain bounding to architectural-decision bounding). What didn’t happen: rediscovering disciplines that DeploySignal had already paid for.
By R78, Tessera ships 440+ tests, a coverage matrix across 6 failure types × 20 parameter variations (R72), a detection envelope across 504 cells / 2,520 trials (R77), and a topology-walk tuning envelope (R78). The audit trail is the project’s git history — every round’s role-tagged commits, cold-eye Reviewer reports, Memorial-Updater outputs, and ESCALATE-resolution patterns. Public.
New disciplines that emerged
Tessera didn’t only inherit disciplines. It produced new ones. Three concrete examples.
OBSERVED-binding scope check (R07 MAJOR-2). In DeploySignal, the “OBSERVED-binding” pattern handled a specific narrow case: PRNG-drift between expected fire counts (architect predicted 20 fires; observed 21; bind OBSERVED=21 with a ±1 tolerance). The pattern was designed for that narrow case.
On Tessera R07, an Architect applied OBSERVED-binding to a different class of deviation: predicted 20-30 fires, observed 0. That’s not PRNG drift; that’s a structural algorithmic gap. But OBSERVED-binding silently extended into the new class, producing a test that asserted firedCount === 0 — a test that would FAIL any future fix that restored detection power and PASS a regression that preserved zero detections. Self-confirming, in the worst possible direction.
The Reviewer’s right-reasons audit caught it. The redesigned ACs used theory-derived bounds (Ville-bound power calculation: firedCount >= 25) and added separate ACs against perturbation-FPR. The discipline that landed: for every OBSERVED-binding, ask “would a future implementation fix matching the architect’s prediction FAIL this test?” If yes, the binding is self-confirming; redesign.
Inherited-testimony empirical verification (R08 MAJOR-2). An Architect drafting round R08 cited a factual claim from R07’s Reviewer: “MCD on the clean fixture produces zero contamination flags.” The claim turned out to be empirically wrong. The R08 spec built downstream prescriptions on the false premise; the Implementer absorbed the conflict and the round shipped wrong work.
The recognition: inherited testimony from a prior round is not equivalent to independent verification. The discipline that landed: for every factual claim about prior-round behavior that the spec cites or builds upon, ask “has this been verified by my own observation, or inherited from prior testimony?” Inherited testimony requires running the relevant command against current production code and recording the OBSERVED output inline. With command, output, and date.
Existing-architectural-surface enforcement. A structural fix rather than a new named discipline. The file-opened question — has the Architect actually opened the cited files, or summarized from memory? — was already in the pre-route checklist. It was declaratively easy to violate: an architect can mentally check the box without actually opening the file. The discipline-application-gap pattern was observed twice within hours in May 2026, both violations citing inherited types from memory, both caught by Reviewer cold-context audit.
The fix: Q-NN-SPEC-TEMPLATE.md now requires a ## Existing architectural surface citation table — file path + pinned SHA + line range + verbatim snippet + date-and-time opened. Empty rows or paraphrased snippets fail the Reviewer audit automatically. A companion script (verify-citations.sh) parses the table, resolves each row against the cited SHA, and prints the actual file content for side-by-side comparison. The discipline became mechanically verifiable rather than self-attested.
R61 architectural-reality discovery
Tessera’s SLICE 3 wave was supposed to land the bi-directional DeploySignal integration as a contained piece of work. R61 surfaced something the spec hadn’t anticipated: a clean engine-npm-extract (eliminating vendoring drift via a shared package) required resolving the types-barrel coupling between vendored-with-deltas surfaces and the core detection algorithms. The work was project-close-magnitude. SLICE 3 couldn’t absorb it.
Anchor’s role in moments like this isn’t to make the surprise go away — it’s to name the discovery cleanly. R61 emitted an architectural-reality memo with the scope assessment, the artifacts already produced, and the deferral recommendation. Phase 4 (dedicated design cycle) was opened to handle the extract; SLICE 3 was rescoped to ship what it could ship (HTTP contract, feed adapter, event consumer). No work was lost; the project-close-magnitude question got its own design phase. The pattern matters because mid-wave architectural discoveries are common in any sufficiently ambitious project. The methodology’s contribution is making them ship-able as deferral artifacts rather than absorbed as silent scope creep.
The lifecycle
Three products, one statistical substrate, three operational questions.
DeploySignal catches before promotion. Tessera observes during steady state. Cairn attributes when something escapes both.
Cairn is the third sibling. When a regression escapes both the deploy gate and steady-state observation and lands in production, Cairn ranks candidate cause-events against incident onset under a Bayesian alignment model — Gaussian timestamp kernel × per-kind prior × evidence-quality boost. The operator gets back ranked attribution of timing-consistent candidates with cited evidence, not “root cause” (a discipline boundary Cairn holds explicitly: this is alignment-based attribution, not causal inference).
Cairn consumes audit streams from the rest of the bundle: DS audit JSONL, Tessera VerdictGroup feed, Anvil chaos-experiment definitions, plus generic external events. The vendoring pattern matters here. Tessera vendors the DS engine at SHA 5a72371 rather than depending on runtime sharing. The bi-directional integration is HTTP contract (engine/ds-integration/), not import. The same is true for Cairn — it reads structured audit records, never engine internals.
Why this composition matters: each product applies the same anytime-valid statistical engine to a different operational question, with explicit contracts at the boundaries. An operator gets pre-promotion verdict, steady-state observation, and postmortem attribution that share statistical guarantees. Not three tools cobbled together; one substrate with three projections.
Cairn gets its own deep dive later in this series. It has its own technical core — the Bayesian alignment math, the per-kind kernels and priors, the suppression rules — and its own honesty disciplines (the “alignment, not causation” carve-out is load-bearing for the pitch and worth its own treatment).
Close
Two open items for Tessera. The engine npm extract is deferred to Phase 4 — a dedicated design cycle, not a SLICE-absorbable piece. The trade-off being made: cleaner package separation at the cost of designing the types-barrel separation carefully rather than rushing it. Real-cluster DCGM validation is also Phase 4 — at v1, Tessera validates against synthetic fixtures derived from public Neuron SDK + JAX topology code + TPU papers. Rented-hardware validation is a Phase 4 candidate.
The methodology now has fifteen-plus named skills. The original ten emerged from DeploySignal. Tessera produced the OBSERVED-binding scope check, the inherited-testimony empirical verification, and the existing-architectural-surface structural fix. Each addition started as a real failure that cost real time; each became a discipline that future projects inherit through the cross-project memorial.
The compounding claim from the Anchor post is now visible in the work. DeploySignal’s first twenty rounds paid for disciplines that Tessera’s first twenty rounds didn’t repeat. Tessera’s failures produced disciplines that the next project won’t repeat either. Project N+1 inherits N’s disciplines plus its own. The cost of starting a new project goes down with each project finished.
The arc of these three posts: build DeploySignal, distill methodology, apply it to Tessera from round 1, watch the disciplines compound. The next post will be about Anvil — what changes when the engine runs against chaos experiments rather than canary deploys. Cairn comes after that. Different math each time, same substrate. The methodology still applies.